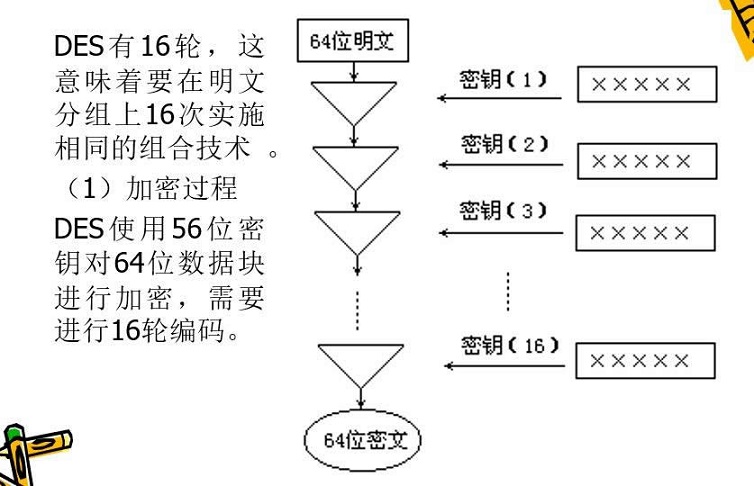
全模态不降智,性能达到开源SOTA

1、视觉编码器:SigLIP-ViT-L/16 优化
标准 ViT (Vision Transformer) 将图像分割为 16×16 像素块,而 SigLIP 通过改进损失函数提升弱监督学习效果。
SigLIP 损失函数:相比传统对比学习使用 softmax 归一化,SigLIP 使用 sigmoid 激活,对噪声标签更鲁棒,特别适合美团内部海量弱标注数据。
SigLIP 损失函数定义:
L siglip = − ∑ i = 1 N ∑ j = 1 M log σ ( s ⋅ y i j ⋅ ⟨ E img ( x i ) , E txt ( t j ) ⟩ ) \mathcal{L}_{\text{siglip}} = -\sum_{i=1}^{N} \sum_{j=1}^{M} \log \sigma(s \cdot y_{ij} \cdot \langle E_{\text{img}}(\mathbf{x}_i), E_{\text{txt}}(\mathbf{t}_j) \rangle) Lsiglip=−i=1∑Nj=1∑Mlogσ(s⋅yij⋅⟨Eimg(xi),Etxt(tj)⟩)
其中:
- N N N 为图像数量, M M M 为文本数量
- y i j ∈ { − 1 , 1 } y_{ij} \in \{-1, 1\} yij∈{−1,1} 为图像-文本对的匹配标签
- s s s 为缩放因子(通常设为 10)
- σ ( z ) = 1 / ( 1 + e − z ) \sigma(z) = 1/(1+e^{-z}) σ(z)=1/(1+e−z) 为 sigmoid 函数
- E img , E txt E_{\text{img}}, E_{\text{txt}} Eimg,Etxt 为图像/文本编码器
2、音频编码器:Whisper 蒸馏优化
完整 Whisper-large-v3 模型含有 30 层 encoder,对端侧部署过于庞大。LongCat 采用分层蒸馏策略:
- 保留前 8 层 transformer (占原始性能的 89%)
- 使用完整 Whisper 作为教师模型,通过知识蒸馏迁移能力
- 添加声学场景分类头,增强非语音理解
蒸馏损失函数:
L distill = α L CE ( y , y ^ ) + β KL ( p teacher ∥ p student ) \mathcal{L}_{\text{distill}} = \alpha \mathcal{L}_{\text{CE}}(y, \hat{y}) + \beta \text{KL}(p_{\text{teacher}} \| p_{\text{student}}) Ldistill=αLCE(y,y^)+βKL(pteacher∥pstudent)
其中:
- L CE \mathcal{L}_{\text{CE}} LCE 为标准交叉熵损失
- KL \text{KL} KL 为 KL 散度,衡量教师与学生输出分布差异
- α = 0.7 , β = 0.3 \alpha=0.7, \beta=0.3 α=0.7,β=0.3 为平衡系数
1. 本站所有资源来源于用户上传和网络,如有侵权请邮件联系站长!
2. 分享目的仅供大家学习和交流,您必须在下载后24小时内删除!
3. 不得使用于非法商业用途,不得违反国家法律。否则后果自负!
4. 本站提供的源码、模板、插件等等其他资源,都不包含技术服务请大家谅解!
5. 如有链接无法下载、失效或广告,请联系管理员处理!
6. 如遇到加密压缩包,请使用WINRAR解压,如遇到无法解压的请联系管理员!
7. 本站有不少源码未能详细测试(解密),不能分辨部分源码是病毒还是误报,所以没有进行任何修改,大家使用前请进行甄别!
66源码网 » 全模态不降智,性能达到开源SOTA